El objetivo del ejercicio es diseñar una pipeline de ingesta y procesado de datos, considerando posibles aspectos que tendría un sistema así en un entorno de producción. Para simplificar la implementación nos centraremos en tres componentes básicos:
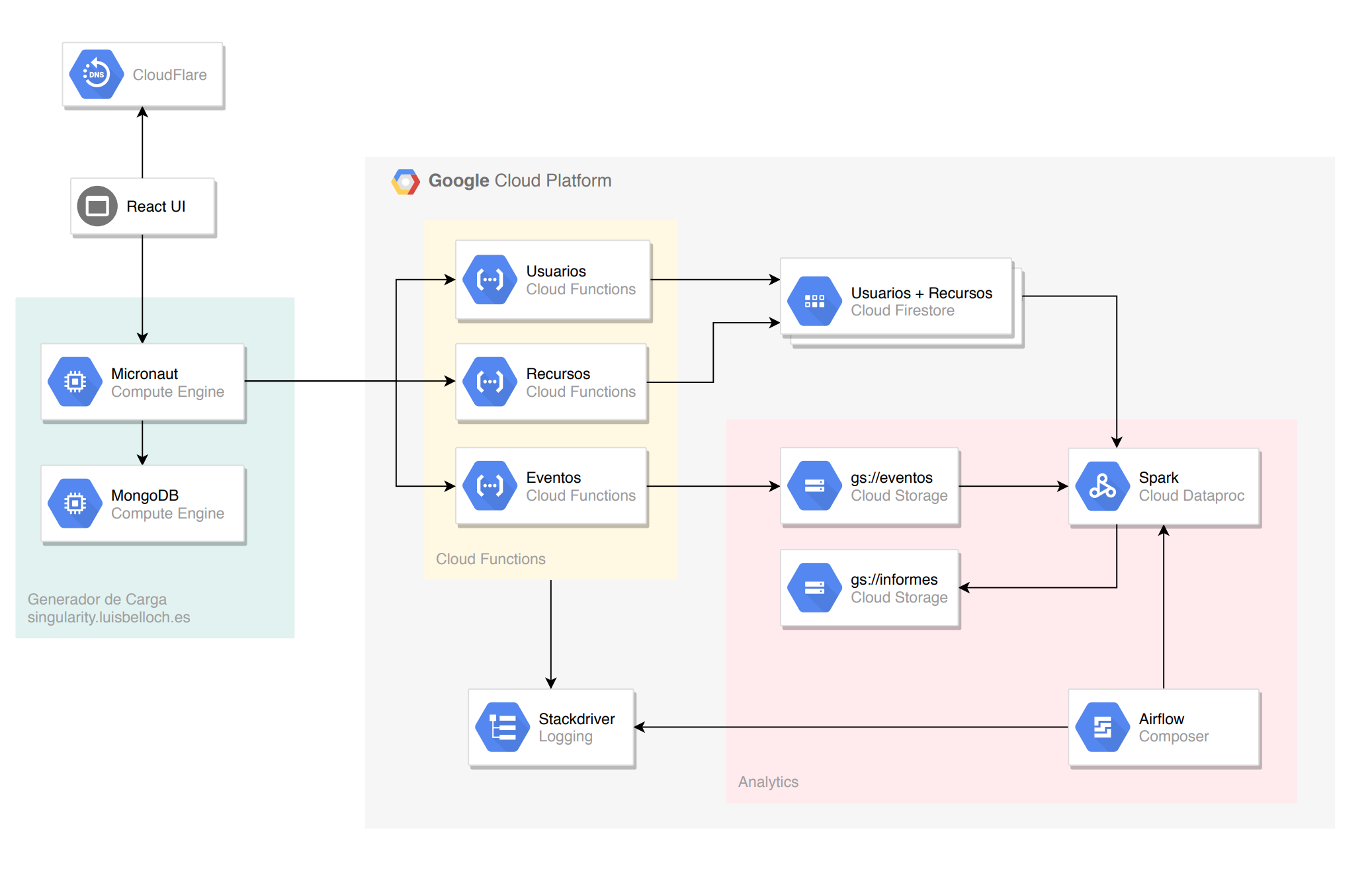
Para implementación utilizaremos componentes de Google Cloud, pero es posible utilizar otros proveedores o tecnologías si cada equipo lo justifica adecuadamente y se mantiene Spark como framework de procesado de datos. En el diagrama siguiente se muestran la propuesta con los diferentes componentes:
Para simular la generación de datos, existe un sistema externo que generará distintos eventos cada pocos segundos. El generador de datos aparece en el diagrama en la parte izquierda, en verde. Es posible habilitar o deshabilitar la generación de datos mediante un panel de control en singularity.luisbelloch.es, donde también puede configurarse la URL donde el generador enviará los datos. El código fuente está disponible en el repositorio de Github.
El servicio de ingesta de datos es el que se encargará de recibir los datos de los eventos generados por el sistema externo y almacenarlos en distintas bases de datos, dependiendo de la naturaleza de los mismos. El sistema a desarrollar debe poder procesar 3 tipos de entidades externas:
Para cada una de las entidades a procesar se desarrollara un endpoint HTTP que recibirá del simulador peticiones en formato JSON y los almacenará en la base de datos. Utilizaremos Cloud Functions para su desarrollo, aunque es posible también hacer uso de Cloud Run y un contenedor específico si se desea. Lo único que se pide es que el endpoint sea capaz de absorber los datos para su posterior procesado.
En cada entidad se ha incluido una descripción de los mensajes en formato Protocol Buffers como referencia.
En clase veremos como desarrollar Cloud Functions en Python. Puede abrirse el repositorio de referencia con el siguiente enlace:

O también clonando directamente el repositorio de Gitlab:
git clone https://gitlab.com/luisbelloch/functions.git
Hemos incluido un Makefile para facilitar la ejecución de los ejemplos. Los distintos targets se muestran ejecutando make help:
functions/hello$ make help
delete Removes deployment
dependencies Installs python dependencies locally
deploy Deploys function
describe Get information about one function
list List all cloud functions deployed in region
test Runs tests locally using pytest
test_curl Sends a sample request using cURL
test_httpie Sends a sample request using HTTPie
En cualquier momento un nuevo recurso (inmueble) puede darse de alta. El servicio debe cumplir este contrato:
syntax = "proto3";
message CreateResourceRequest {
string id = 1; // identificador inmueble
string name = 2; // dirección del immueble
string category_id = 3; // clase de inmueble
string provider_id = 4; // persona que ofrece el el inmueble en alquiler
bool promotion = 5; // inmueble en promoción
}
message CreateResourceResponse {
string external_id = 1;
}
service Resource {
rpc CreateResource (CreateResourceRequest) returns (CreateResourceResponse);
}
Es posible obtener una lista de todos los inmuebles en el sistema mediante la url http://singularity.luisbelloch.es/v1/airbnb/resources
Se recomienda guardar los datos en Firestore, ya que el volumen no es muy alto y el esquema de datos es de tipo documental. Puede también optarse por otro almacenamiento, siempre que en el entregable se justifique adecuadamente.
En cualquier momento puede darse de alta nuevos usuarios. El servicio debe cumplir este contrato:
syntax = "proto3";
message CreateUserRequest {
string email = 1;
string name = 2;
int32 age = 3;
}
message CreateUserResponse {
string external_id = 1;
}
service User {
rpc CreateUser (CreateUserRequest) returns (CreateUserResponse);
}
Es importante tener en cuenta varias cosas:
http://singularity.luisbelloch.es/v1/airbnb/users Se recomienda guardar los datos en Firestore, ya que el volumen no es muy alto y el esquema de datos es de tipo documental. Puede también optarse por otro almacenamiento, siempre que en el entregable se justifique adecuadamente.
Aproximadamente cada segundo, el servidor de eventos generará sucesos para que el sistema los considere. Un ejemplo de evento puede ser el siguiente:
En un determinado momento, un usuario alquila un piso en la 'Avenida de Francia' al cliente 'Pedro Martínez' durante tres días.
Dicho evento sigue el siguiente contrato:
syntax = "proto3";
import "google/protobuf/duration.proto";
import "google/protobuf/timestamp.proto";
message Event {
string event_id = 1;
google.protobuf.Timestamp event_time = 2;
google.protobuf.Timestamp process_time = 3;
string resource_id = 4; // identificador inmueble
string user_id = 5; // identificador del usuario
string country_code = 6; // ISO3166
google.protobuf.Duration duration = 7;
double item_price = 8;
}
message EventResponse {
string external_id = 1;
}
service Events {
rpc Process (Event) returns (EventResponse);
}
Es importante saber que los eventos sólo serán generados para aquellos Usuarios o Recursos previamente guardados.
En este caso se recomienda utilizar Cloud Storage o BigQuery para los eventos, pero puede utilizarse cualquier otro sistema con su correspondiente justificación.
Es posible limpiar todos los registros generados hasta el momento, incluidos los registros de auditoría. Para ello hay que lanzar una petición POST a la siguiente url:
curl -X POST https://singularity.luisbelloch.es/v1/airbnb/reset
Es posible arrancar la aplicación que genera los eventos para realizar pruebas, sin depender de singularity.luisbelloch.es. Para ello, lanza el contenedor de Docker directamente:
docker run -p 8080:8080 -ti luisbelloch/singularity
La aplicación estará disponible en localhost:8080.
Adicionalmente, se pueden generar datos de forma local y volcarlos a un archivo. Esto puede simplificar el desarrollo de los programas de Spark en la parte 3. Para generar 10 eventos:
docker run -ti luisbelloch/singularity_mock evento 10 > eventos.jsonl
Se pueden también generar recursos o usuarios:
docker run -ti luisbelloch/singularity_mock recurso 10
docker run -ti luisbelloch/singularity_mock usuario 10
Para los entregables de clase los datos tienen que haber sido guardados mediante las Cloud Functions desarrolladas en este apartado.
Generar mediante Spark un informe diario de los 10 inmuebles más alquilados por día y por categoría. Guardar en un bucket de Cloud Storage en formato CSV, con la siguiente estructura:
position|date|categoryId|categoryName|resourceId|resourceName
La definición de las categorías puede extraerse de http://singularity.luisbelloch.es/v1/airbnb/categories al inicio del proceso.
Generar, mediante Spark, un fichero mensual con la cantidad que Airbnb debe pagar a cada persona que ofrece el el inmueble en alquiler. Cada pago tiene una clase de asociada que indica el porcentaje que se ha de pagar sobre el total, excepto en algunos inmuebles que vienen con el flag promotion:true, en cuyo caso la cantidad total a pagar es cero.
Los archivos han de guardarse en Cloud Storage en formato json por lineas:
{ "date": "2019-02", "providerId": "BGA543T", "resourceId": "P401", "amount": 340.29 }
{ "date": "2019-02", "providerId": "BGA543T", "resourceId": "P402", "amount": 231.00 }
La cantidad debe estar expresada en dólares americanos. Para ello, ha de convertirse el importe de cada pago a USD. Puede obtenerse una lista de cambios de divisas mediante:
GET https://bigdata.luisbelloch.es/exchange_rates/usd
La correspondencia entre paises y monedas puede descargarse desde:
GET https://bigdata.luisbelloch.es/countries.csv
Este fichero ha de generarse todos los meses, por lo que tenéis que buscar una forma de automatizar este proceso para que no exista intervención humana. Incluid la configuración del servicio en el entregable. No es necesario utilizar Airflow, puedes buscar otras alternativas.
Los precios por clase de se pueden obtener desde la siguiente URL http://singularity.luisbelloch.es/v1/airbnb/categories y siguen el siguiente formato:
{
"categoryId": "Z45",
"categoryName": "Villa de Lujo",
"percent": 0.12
}
Mediante Spark, extraer dos informes mensuales de utilización de cada inmueble, uno segmentado por país y otro por zona horaria. Los archivos deben guardarse en Cloud Storage en formato Parquet, con las siguientes columnas:
date,resourceId,countryCode,usagePercentTotal,usagePercentRelativeCountry,totalDurationInSec
Donde las columnas significan:
usagePercentTotal - Porcentaje de uso total de cada inmueble relativo al resto.usagePercentRelativeCountry - Porcentaje de uso relativo al país.totalDurationInSec - Uso total por inmueble, en segundos.Y en el caso de las zonas horarias:
date,resourceId,timeZone,usagePercentTotal,usagePercentRelativeTz,totalDurationInSec
Para este ejercicio puede utilizarse tanto Spark como BigQuery. En el caso de utilizar BigQuery, incluir en el entregable los scripts de configuración y carga de datos.
¿Puedes encontrar una forma de computar dichos porcentajes en streaming?
El entregable de la asignatura puede realizarse por grupos y debe contener:
Opcionalmente, fuera de evaluación:
pip3 install httpieairbnb - 2024-07-11T10:02:43.991Z - Commit: fe8f107